Een ultrasnel coderingsmodel aangedreven door Cerebras
Vorige maand kondigde OpenAI een samenwerking aan met Cerebras, een AI-startup die purpose-built systemen ontwikkelt om lange output van AI-modellen te versnellen. Destijds gaf OpenAI aan dat het de low-latency-technologie van Cerebras in fasen zou integreren in haar inference-stack om verschillende workloads te ondersteunen, waaronder het genereren van code en het creëren van afbeeldingen.
Vandaag kondigt OpenAI een onderzoeksvoorbeeld aan van GPT-5.3-Codex-Spark, een kleinere versie van GPT-5.3-Codex, ontworpen voor realtime coderingsscenario’s en aangedreven door Cerebras’ Wafer Scale Engine 3. OpenAI beweert dat Codex-Spark meer dan 1.000 tokens per seconde kan leveren, terwijl het een sterke capaciteit behoudt. Omdat het echter een kleiner model is, wordt van GPT-5.3-Codex-Spark niet verwacht dat het net zo goed presteert als de volledige GPT-5.3-Codex; OpenAI geeft aan dat de prestaties liggen tussen GPT-5.3-Codex en GPT-5.1-Codex-Mini.
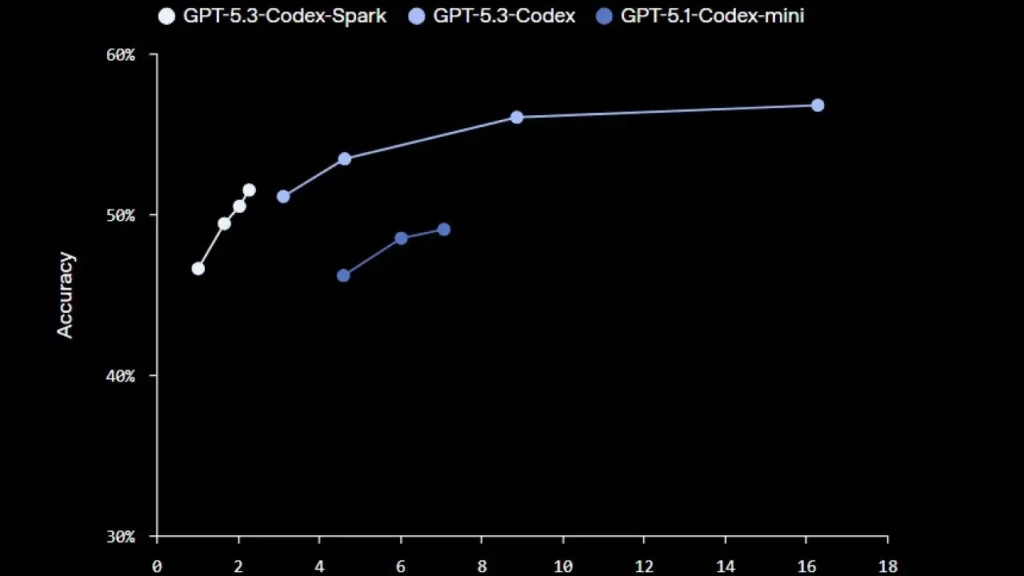
Vooralsnog ondersteunt Codex-Spark een contextvenster van 128K en alleen tekstinput. OpenAI is van plan in de toekomst ondersteuning toe te voegen voor grotere modellen, langere contexten en multimodale input. Omdat dit een beperkte uitrol is voor ChatGPT Pro-gebruikers, heeft het model eigen snelheidslimieten, hoewel het gebruik niet meetelt voor de standaardlimieten. Bij een plotselinge stijging in vraag kan OpenAI de toegang verder beperken of gebruikers tijdelijk in een wachtrij plaatsen om de betrouwbaarheid te waarborgen.
Abonnees op ChatGPT Pro kunnen het ultrasnelle model uitproberen door te updaten naar de nieuwste versies van de Codex-app, CLI en VS Code-extensie. OpenAI maakt Codex-Spark ook via de API beschikbaar voor een kleine groep designpartners om te leren hoe ontwikkelaars het willen integreren in andere producten en diensten.
OpenAI benadrukte tevens dat GPU’s nog steeds het primaire platform zijn voor berekeningen binnen haar trainings- en inference-pijplijnen voor breed gebruik. Tegelijkertijd positioneerde het de technologie van Cerebras als beter geschikt voor extreem latency-gevoelige Codex-workloads. Het bedrijf voegde daaraan toe dat GPU’s en Cerebras-systemen in één workload gecombineerd kunnen worden om de beste algehele prestaties te bereiken.